
深度学习中的显卡介绍
1 用于深度学习的GPU介绍
1.1 目前常用于深度学习的GPU型号和性能参数
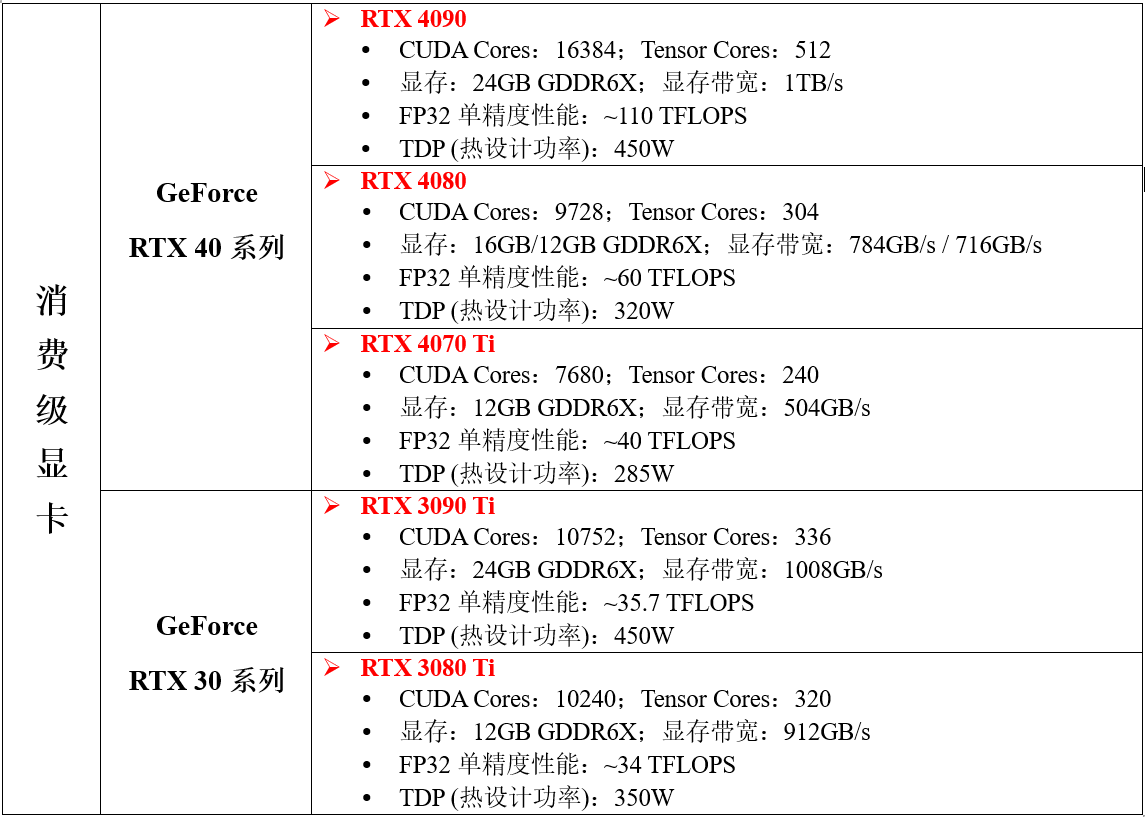
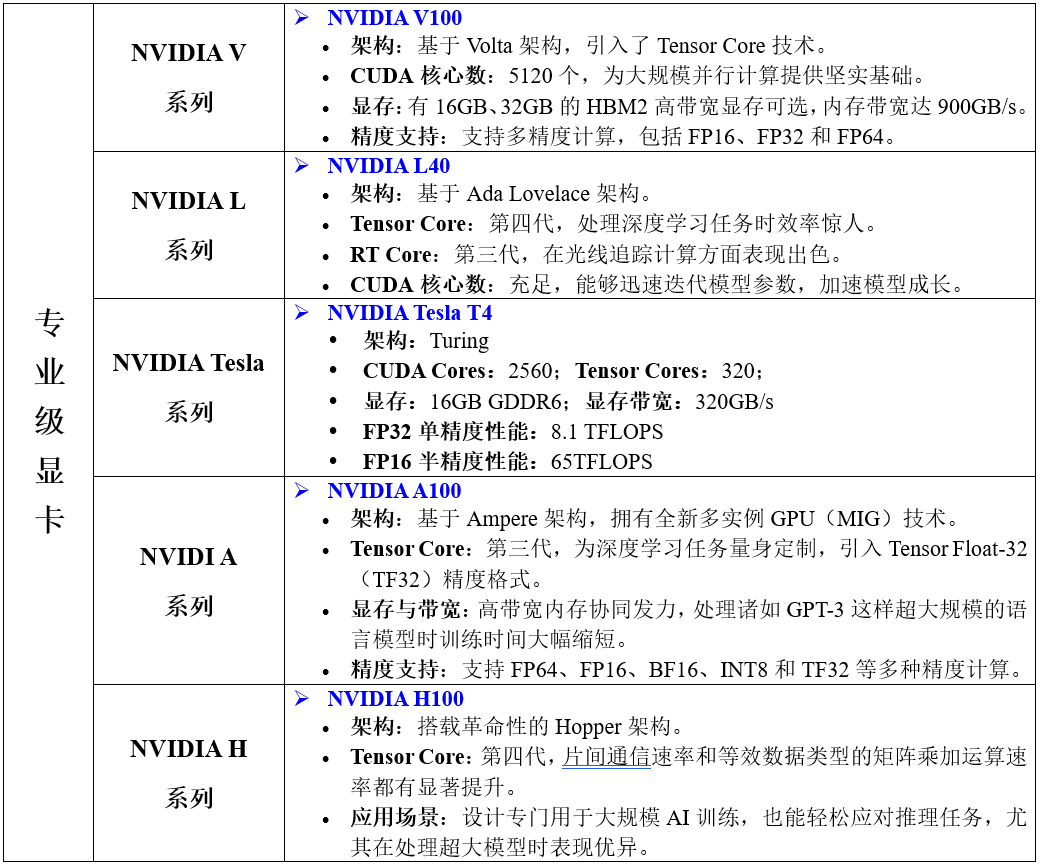
补充说明:

1.2 显卡选购建议
1.2.1 入门级 - 初学者或轻度用户
如果你刚开始接触深度学习,或者只是做一些简单的实验和小规模模型训练,那么以下显卡可能就足够了:

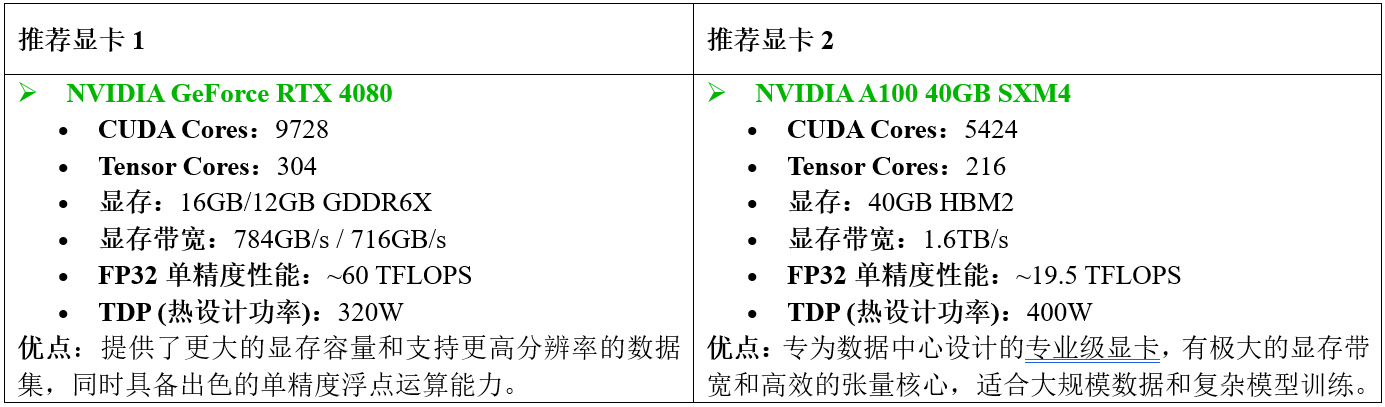
1.2.2 中级 - 研究员或开发者
对于那些需要更强大的计算能力来进行更复杂的模型训练或研究工作的人群来说,可以考虑以下显卡:
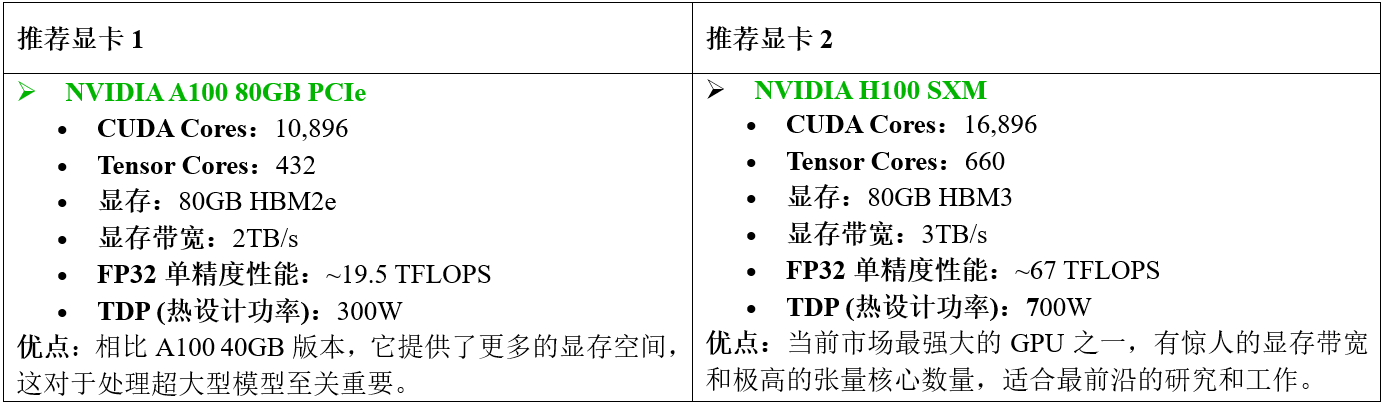
1.2.3 高级/专业级 - 高端研究机构或企业
当涉及到非常大的数据集、极其复杂的模型架构以及需要快速迭代和高吞吐量时,应该选择最顶级的专业级显卡:
2 CUDA概念介绍
2.1 转载自其他网站的Cuda概念
| 🐹 什么是CUDA: CUDA —— 英伟达2006年推出的计算API,相当于是一种可以调用英伟达GPU的一个平合。一般计算机最重要的芯片有两个:CPU和GPU。CPU是中央处理器,GPU是图形处理器。 编程语言(C/C++等)只能调用CPU,不能调用GPU。我们想让GPU强大的并行化能力充分发挥,编写一些可以并行化的程序在GPU上运行能够快速获得运行结果,所以需要一个在编程语言(C/C++等)和底层GPU这个物理芯片之间有一个可以沟通连接的东西,因此英伟达NVIDIA搞出了一个叫做Cuda的平台。简单来说,可以认为Cuda是对C/C++语言进行了扩展,允许开发者编写运行在NVIDIA GPU上的代码。 有了这个平台,你就可以使用编程语言(C/C++等)调用GPU处理大量的并行化任务,而不需要重新设计一个全新的能直接在GPU上直接运行的编程语言,节省了大量的学习成本。有了Cuda平台,就可以使得显卡不仅仅是进行图像像素等的处理,还能进行一些更加通用的运算,比如人工智能等算法需要大量的矩阵运算,这需要很强的并行化处理能力来加快运算,于是我们可以利用Cuda编写程序让这部分需要并行运算的代码在GPU上跑,而不是在并行化能力较弱的CPU上跑。 什么是CUDA - 苦魔-浪人 - 哔哩哔哩 |
🎅 Cuda是什么:
没有CUDA就没有今天人工智能产业的繁荣,那CUDA它是个啥、它是如何诞生的。
我们先从老黄和他的英伟达说起。黄仁勋1963年生于台南,1993年喜欢游戏的黄仁勋和另外两位芯片设计师Chris Malachowsky、Curtis Priem共同创立了英伟达,他们的眼光瞄准了正在蓬勃成长的个人电脑与游戏机市场,此时一些3D游戏开始崭露头角,而3D游戏必须有专业的图形显示处理器来帮助CPU加速图像渲染,这也就是我们今天常说的显卡原型。显卡中的核心就是图形计算器GPU,不过GPU这个词语出现和流行要晚一点。1999年英伟达发布其革命性产品 —— Geforce 256,其芯片采用220纳米制造,拥有2300万个晶体管,并首次把以往需要CPU处理的坐标转换和光源计算直接集成到显卡这个硬件中。这款显卡计算性能大幅跃升的同时减少了游戏对CPU计算的依赖,它也因此常被宣称为世界上第一个GPU。这时期接连涌现的GPU,为了满足市场对画面真实感的需求,允许开发人员编写在每个像素上运行的程序,这些程序很简单,可能只有几条指令,但是它们在屏幕上的每个像素背后运行:
 想象一下,如果一个游戏画面是100万像素,每个像素每秒运行60次,那么这个游戏画面本质上是一个大规模并行的程序,而这种大规模的并行计算让眼尖的人看到了其中蕴含的线性代数的矩阵乘法的影子,而涉及这类数学的领域往往都是数值建模、科学计算等,而今天极为重要的人工智能更是离不开这类数学。
能不能把GPU从专用的图形计算变为适合这类数学的通用计算呢?当然可能有人这时候会想起电脑的中央处理器CPU就是通用计算,刚刚提到的科学计算人工智能等等不能用CPU算吗?
答案是:能是能,只是虽然CPU的核心计算和处理复杂任务的能力相比GPU更强,但CPU核心的数量比GPU少得多:
想象一下,如果一个游戏画面是100万像素,每个像素每秒运行60次,那么这个游戏画面本质上是一个大规模并行的程序,而这种大规模的并行计算让眼尖的人看到了其中蕴含的线性代数的矩阵乘法的影子,而涉及这类数学的领域往往都是数值建模、科学计算等,而今天极为重要的人工智能更是离不开这类数学。
能不能把GPU从专用的图形计算变为适合这类数学的通用计算呢?当然可能有人这时候会想起电脑的中央处理器CPU就是通用计算,刚刚提到的科学计算人工智能等等不能用CPU算吗?
答案是:能是能,只是虽然CPU的核心计算和处理复杂任务的能力相比GPU更强,但CPU核心的数量比GPU少得多:
 > PS:既然GPU核心这么多,可能会有人想把CPU做大,给CPU堆核心数量不行吗?
>
> 回答:物理特性限制,cpu不能做那么大。良品率等原因导致核心大小和数量有极限,一般cpu是要比gpu物理尺寸大的,显卡只是散热模具大,核心和cpu差不多大,其他的你想象成主板也可以。
CPU更适合做一个接一个的串行指令,GPU更适合做同时的并行指令,所以GPU的这种能力更适合。但是此时的程序员想在GPU上编程进行通用计算是很难的事情,想要将图形处理器从游戏渲染部署应用到一般计算领域,这就需要把这些通用计算的算法转化映射到这些GPU的纹理、三角形、像素等图形基元。而这种任务即便是对高级的图形开发人员来说也很难。
斯坦福大学图形实验室的伊恩·巴克不畏难,他带领团队搞了一个 BrookGPU项目 ,这个项日主要就是研究在GPU上进行通用编程并为开发人员提供更方便的GPU编程工具。这个项目在ATI(今AMD)、英伟达、IBM、索尼以及国防部幸能源部等机构的技术和资金支持下取得了不错的成果。他们通过引入Brook编程语言,使得C语言可以拓展涵盖简单的数据并行构造,从而实现GPU作为流处理协处理器的通用计算功能。
而老黄也看到了这个项目的潜力,因为显卡想模拟显示更加真实的现实世界,就需要引入更多的物理规律,而这些规律的科学计算很依赖GPU的通用计算能力,所以老黄想借助伊恩·巴克,把英伟达的GPU打造成强大的超级计算机。伊恩·巴克毕业后顺势加入了英伟达,并从04年开始主导新项目——CUDA(统一计算设备架构, Compute Unified Device Architeeture)。这是一种并行计算架构和编程模型,专门用于英伟达的GPU。通过CUDA,开发人员可以基于C语言等编程语言拓展,编写可以调用GPU进行通用计算的程序。但是Cuda的科学计算功能对于当时大部分买来打游戏的消费者来说压根用不到,英伟达一度要破产。直到2011年曾经因曼哈顿计划建立的橡树岭国家实验室正在升级打造超级计算机泰坦,他们看到了GPU作为通用计算的价值,所以采购了大量英伟达的GPU,泰坦也是世界上第一台以通用图形处理器作为主要数据处理器的超级计算机。并在2012年11月到2013年6月间,保持了世界上最快超级计算机的称号。
英伟达的王牌杀手:CUDA的诞生 - 哔哩哔哩
> PS:既然GPU核心这么多,可能会有人想把CPU做大,给CPU堆核心数量不行吗?
>
> 回答:物理特性限制,cpu不能做那么大。良品率等原因导致核心大小和数量有极限,一般cpu是要比gpu物理尺寸大的,显卡只是散热模具大,核心和cpu差不多大,其他的你想象成主板也可以。
CPU更适合做一个接一个的串行指令,GPU更适合做同时的并行指令,所以GPU的这种能力更适合。但是此时的程序员想在GPU上编程进行通用计算是很难的事情,想要将图形处理器从游戏渲染部署应用到一般计算领域,这就需要把这些通用计算的算法转化映射到这些GPU的纹理、三角形、像素等图形基元。而这种任务即便是对高级的图形开发人员来说也很难。
斯坦福大学图形实验室的伊恩·巴克不畏难,他带领团队搞了一个 BrookGPU项目 ,这个项日主要就是研究在GPU上进行通用编程并为开发人员提供更方便的GPU编程工具。这个项目在ATI(今AMD)、英伟达、IBM、索尼以及国防部幸能源部等机构的技术和资金支持下取得了不错的成果。他们通过引入Brook编程语言,使得C语言可以拓展涵盖简单的数据并行构造,从而实现GPU作为流处理协处理器的通用计算功能。
而老黄也看到了这个项目的潜力,因为显卡想模拟显示更加真实的现实世界,就需要引入更多的物理规律,而这些规律的科学计算很依赖GPU的通用计算能力,所以老黄想借助伊恩·巴克,把英伟达的GPU打造成强大的超级计算机。伊恩·巴克毕业后顺势加入了英伟达,并从04年开始主导新项目——CUDA(统一计算设备架构, Compute Unified Device Architeeture)。这是一种并行计算架构和编程模型,专门用于英伟达的GPU。通过CUDA,开发人员可以基于C语言等编程语言拓展,编写可以调用GPU进行通用计算的程序。但是Cuda的科学计算功能对于当时大部分买来打游戏的消费者来说压根用不到,英伟达一度要破产。直到2011年曾经因曼哈顿计划建立的橡树岭国家实验室正在升级打造超级计算机泰坦,他们看到了GPU作为通用计算的价值,所以采购了大量英伟达的GPU,泰坦也是世界上第一台以通用图形处理器作为主要数据处理器的超级计算机。并在2012年11月到2013年6月间,保持了世界上最快超级计算机的称号。
英伟达的王牌杀手:CUDA的诞生 - 哔哩哔哩
|
🚀 一文揭开NVIDIA CUDA神秘面纱:
今天我们来聊一下人工智能生态相关技术:用于加速构建AI核心算力的GPU编程框架 —— CUDA。
你一定听说过CUDA,并了解这玩意与NVIDIA GPU密切相关。然而,关于CUDA的具体定义和功能,许多人仍然心存疑惑,一脸懵逼。CUDA是一个与GPU进行通信的库吗?如果是,它属于C++还是 Python库?或者,CUDA实际上是一个用于GPU的编译器?了解这些问题有助于更好地掌握CUDA的核心特性及其在GPU加速中的作用。
CUDA,全称为 “ Compute Unified Device Architecture”,即“计算统一设备架构”,是NVIDIA推出的一套强大并行计算平台和编程模型框架,为开发人员提供了加速计算密集型应用的完整解决方案。CUDA包含运行时内核、设备驱动程序、优化库、开发工具和丰富的API组合,使得开发人员能够在支持CUDA的GPU上运行代码,大幅提升应用程序的性能。这一平台尤为适合用于处理大规模并行任务,如深度学习、科学计算以及图像处理等领域。
通常而言,“CUDA” 不仅指平台本身,也可指为充分利用NVIDIA GPU的计算能力而编写的代码,这些代码多采用C++和Python等语言编写,以充分发挥GPU加速的优势。借助CUDA,开发人员能够更加轻松地将复杂的计算任务转移至GPU运行,极大提升应用程序的运行效率。
因此,总结起来,可以得出如下结论:CUDA不仅仅是一个简单的库,它是一个完整的平台,为开发者提供了利用GPU进行高效并行计算的全方位支持。这个平台的核心组件包括:
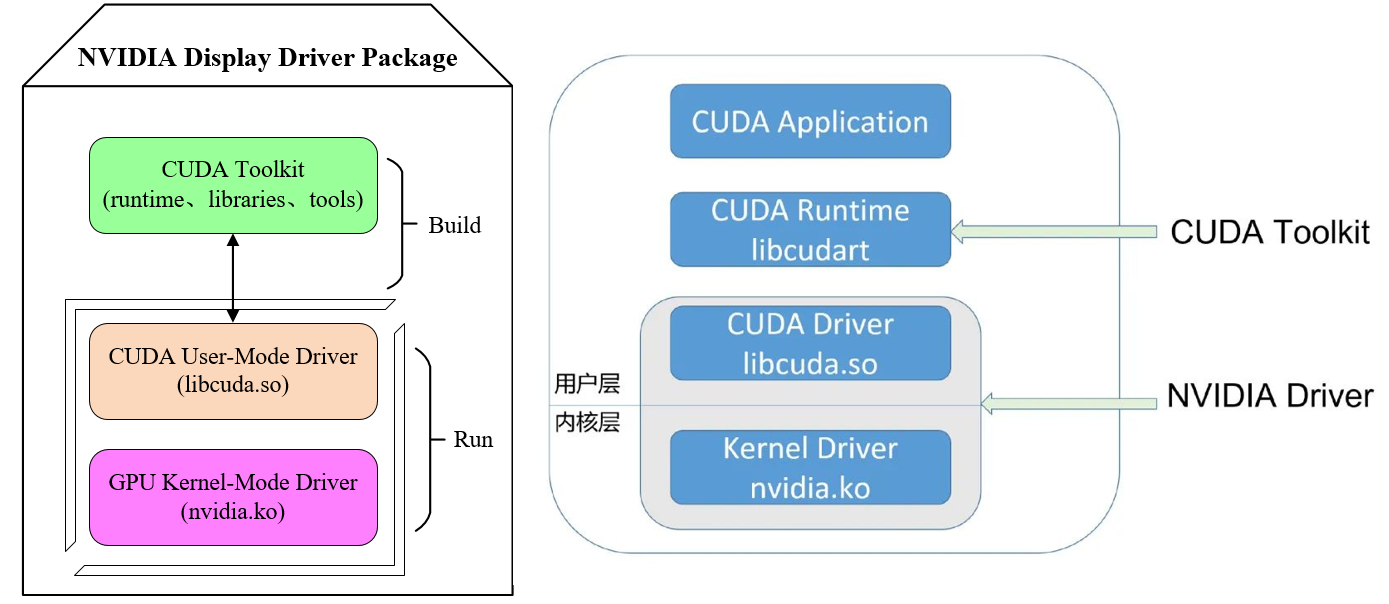 CUDA到底是什么:
(1)CUDA C/C++:这是CUDA为并行编程所扩展的C++语言,专为在GPU上编写并行代码而设计。开发者可以使用熟悉的C++语法结构,通过特定的编程模型定义GPU任务,让代码更高效地在多线程环境中执行。
(2)CUDA 驱动程序:这一组件连接操作系统与GPU,提供底层硬件访问接口。驱动程序的主要作用是管理CPU与GPU之间的数据传输,并协调它们的计算资源。它确保了硬件和操作系统的兼容性,是CUDA代码高效运行的基础。
(3)CUDA 运行时库(cudart):运行时库为开发者提供了丰富的API,便于管理GPU内存、启动GPU内核(即并行任务)、同步线程等。它简化了开发者的工作流程,使得在GPU上运行并行程序的流程更加流畅和高效。
(4)CUDA 工具链(ctk):包括编译器、链接器、调试器等工具,这些工具用于将CUDA代码编译成GPU可执行的二进制指令。工具链中的编译器将C++代码和CUDA内核代码一同处理,使其适应GPU的架构;而调试器和分析工具帮助开发者优化性能和排查问题。
相关的环境变量可参考如下:
1.
CUDA到底是什么:
(1)CUDA C/C++:这是CUDA为并行编程所扩展的C++语言,专为在GPU上编写并行代码而设计。开发者可以使用熟悉的C++语法结构,通过特定的编程模型定义GPU任务,让代码更高效地在多线程环境中执行。
(2)CUDA 驱动程序:这一组件连接操作系统与GPU,提供底层硬件访问接口。驱动程序的主要作用是管理CPU与GPU之间的数据传输,并协调它们的计算资源。它确保了硬件和操作系统的兼容性,是CUDA代码高效运行的基础。
(3)CUDA 运行时库(cudart):运行时库为开发者提供了丰富的API,便于管理GPU内存、启动GPU内核(即并行任务)、同步线程等。它简化了开发者的工作流程,使得在GPU上运行并行程序的流程更加流畅和高效。
(4)CUDA 工具链(ctk):包括编译器、链接器、调试器等工具,这些工具用于将CUDA代码编译成GPU可执行的二进制指令。工具链中的编译器将C++代码和CUDA内核代码一同处理,使其适应GPU的架构;而调试器和分析工具帮助开发者优化性能和排查问题。
相关的环境变量可参考如下:
1. $CUDA_HOME是系统CUDA的路径,看起来像/usr/local/cuda,它可能链接到特定版本/usr/local/cuda-X.X。
2. `$LD_LIBRARY_PATH/`是一个帮助应用程序查找链接库的变量。您可能想要包含$CUDA_HOME/lib的路径。
3. `$PATH`应该包含一个通往$CUDA_HOME/bin的路径。
借助这一完整的开发平台,开发者能够充分挖掘NVIDIA GPU的计算潜力,将复杂的并行计算任务高效地分配至GPU上执行,从而实现应用程序性能的极大提升。
CUDA是如何工作的
现代GPU由数千个小型计算单元组成,这些单元被称为CUDA核心。CUDA核心能够高效并行工作,使GPU能够快速处理那些可以分解为多个小型独立操作的任务。这种架构使得GPU不仅适用于图形渲染任务,也适用于计算密集型的科学计算和机器学习等非图形任务。
作为NVIDIA提供的一个计算平台和编程模型,CUDA专门为GPU开放了这些强大的并行处理能力。通过CUDA,开发者可以编写代码,将复杂的计算任务移交给GPU。以下是CUDA的工作原理:
并行处理
CUDA将计算任务分解为多个可以独立运行的小任务,并将这些任务分配到多个CUDA核心上并行执行。这样一来,与传统CPU顺序执行的模式相比,GPU可以在相同时间内完成更多的计算,从而极大地提升计算效率。
线程和块的架构
在CUDA编程模型中,计算任务被进一步划分为线程,每个线程独立处理一部分数据。这些线程被组织成块,每个块中包含一定数量的线程。这种层次化结构不仅便于管理海量线程,还提高了执行效率。多个线程块可以同时运行,使得整个任务可以快速并行完成。
SIMD架构
CUDA核心采用单指令多数据(Single Instruction Multiple Data,SIMD)架构。这意味着单条指令可以对多个数据元素同时执行操作。例如,可以用一条指令对大量数据元素进行相同的计算,从而加快数值计算的速度。这种架构对矩阵运算、向量处理等高并行任务极为高效,特别适用于深度学习模型训练、图像处理和模拟仿真等领域。
基于这些特性,CUDA不仅为高性能并行计算提供了直接途径,也将NVIDIA GPU的强大计算潜力拓展至科学计算、人工智能、图像识别等领域。
CUDA编程模型
在CUDA编程中,开发者通常需要编写两部分代码:主机代码(Host Code)和设备代码(Device Code) 。主机代码在CPU上运行,负责与GPU进行交互,包括数据传输和资源管理;而设备代码则在GPU上执行,承担主要计算任务。二者相互配合,充分利用CPU和GPU的协同处理能力,以达到高效并行计算的目的。
主机代码(Host Code)
主机代码运行在CPU上,负责控制整个程序的逻辑流程。它管理CPU和GPU之间的数据传输,分配和释放GPU资源,并配置GPU内核参数。这部分代码不仅定义了如何组织数据并将其发送到GPU,还包含了启动设备代码的指令,从而让GPU接管计算密集的任务。主机代码起到管理和协调的作用,确保CPU与GPU之间的高效协作。
此部分包括数据传输、内存管理、以及启动 GPU 内核等,具体功能可参考如下所示:
1. 数据传输管理:主机代码负责在 CPU 和 GPU 之间传输数据。由于 CPU 和 GPU 通常使用不同的内存系统,主机代码需要在两者之间复制数据。例如,将需要处理的数据从主机内存(CPU 内存)传输到设备内存(GPU 内存),并在处理完成后将结果从 GPU 内存传回 CPU 内存。这种数据传输是耗时的,因此在实际应用中需要尽量减少传输频率,并优化数据大小,以降低延迟。
2. 内存分配与管理:主机代码分配 GPU 内存空间,为后续的计算提供储存资源。CUDA API 提供了多种内存管理函数(如 cudaMalloc 和 cudaFree),允许开发者在 GPU 上动态分配和释放内存。合理的内存分配策略可以有效提高内存使用效率,防止 GPU 内存溢出。
3. 内核配置与调度:在主机代码中,开发者可以配置内核启动参数(如线程数和线程块数)并决定内核在 GPU 上的执行方式。通过优化这些参数,主机代码能够显著提升程序的执行效率
设备代码(Device Code)
设备代码编写的核心部分是在GPU上执行的计算函数,通常被称为内核(Kernel)。每个内核函数在GPU的众多CUDA核心上并行执行,能够快速处理大量数据。设备代码专注于数据密集型的计算任务,在执行过程中充分利用GPU的并行计算能力,使得计算速度比传统的串行处理有显著提升。
设备代码定义了GPU的计算逻辑,使用CUDA内核来并行处理大量数据。
1. 内核函数(Kernel Function):设备代码的核心是内核函数,即在GPU的多个线程上同时执行的函数。内核函数由__global__关键字标识,表示该函数将在设备端(GPU)执行。内核函数与普通的 C/C++ 函数不同,它必须是无返回值的,因为所有输出结果都要通过修改传入的指针或GPU内存来传递。
2. 线程和线程块的组织:在设备代码中,计算任务被分解为多个线程,这些线程组成线程块(Block),多个线程块组成一个线程网格(Grid)。CUDA 提供了 threadIdx、blockIdx 等内置变量来获取线程的索引,从而让每个线程在数据中找到属于自己的计算任务。这种方式使得设备代码可以非常高效地并行处理数据集中的每个元素。
3. 并行算法优化:在设备代码中,CUDA编程可以实现多个并行优化技术,如减少分支、优化内存访问模式(如减少全局内存访问和提高共享内存利用率),这些优化有助于最大化利用GPU计算资源,提高设备代码执行速度。
内核启动
内核启动是CUDA编程的关键步骤,由主机代码启动设备代码内核,在GPU上触发执行。内核启动参数指定了GPU上线程的数量和分布方式,使内核函数可以通过大量线程并行运行,从而加快数据处理速度。通过适当配置内核,CUDA编程能以更优的方式利用GPU资源,提高应用的计算效率。
在整个体系中,这一步骤至关重要,它控制了设备代码的并行性、效率及运行行为。具体可参考如下:
1. 内核启动语法:CUDA 使用特殊的语法<<启动内核函数。例如:kernel<<,其中numBlocks表示线程块的数量,threadsPerBlock表示每个线程块中包含的线程数。开发者可以根据数据集的大小和GPU的计算能力选择合适的线程块和线程数量。
2. 并行化控制:通过指定线程块数和线程数,内核启动控制了GPU的并行粒度。较大的数据集通常需要更多的线程和线程块来充分利用GPU的并行能力。合理配置内核启动参数,可以平衡GPU的并行工作负载,避免资源浪费或过载现象。
3. 同步与异步执行:内核启动后,GPU可以异步执行任务,CPU继续进行其他操作,直至需要等待GPU完成。开发者可以利用这种异步特性,使程序在CPU和GPU间并行执行,达到更高的并行效率。此外,CUDA提供了同步函数(如cudaDeviceSynchronize),确保CPU在需要时等待GPU完成所有操作,避免数据不一致的问题。
通过有效协调这三者,CUDA编程能够实现对数据密集型任务的高速并行处理,为高性能计算提供了一个极具扩展性的解决方案。
CUDA内存层次结构体系
在CUDA编程中,GPU内存的结构是多层次的,具有不同的速度和容量特性。CUDA提供了多种内存类型,用于不同的数据存储需求。合理利用这些内存可以显著提升计算效率。以下是各类内存的详细描述:
全局内存(Global Memory)
全局内存是GPU上容量最大的存储空间,通常为几GB,并且是GPU的主要数据存储区。全局内存可以被所有线程访问,也可以与CPU共享数据,但其访问速度相对较慢(相对于其他GPU内存类型而言),因此需要避免频繁访问。数据传输操作也较耗时,因此全局内存常用于存储较大的数据集,但会优先考虑数据访问的批处理或其他缓存策略来减少其频繁调用。
通常而言,全局内存主要适用于存储程序的大部分输入输出数据,尤其是需要GPU和CPU共享的大容量数据。
示例:在矩阵乘法中,两个矩阵的元素可以存储在全局内存中,以便所有线程都可以访问。
|
2.2 关于BrookGPU的介绍
2.2.1 BrookGPU是什么
BrookGPU是一种针对图形处理器(GPU)的编程语言扩展,基于ANSI C(ANSI C标准,也称为C89或C90标准,是C语言的一种标准规范)语言,旨在简化和优化数据并行计算。它由斯坦福大学图形实验室开发,最初是为了在GPU上进行通用计算而设计。
核心概念,BrookGPU的核心概念包括流(Streams)和内核(Kernels):
- 流(Streams):流是BrookGPU中的一种数据类型,代表一系列可以并行处理的数据。流的声明类似于C语言中的数组,但具有并行处理的特性。
- 内核(Kernels):内核是在GPU上执行的函数,用于处理流中的数据。
设计目标
- BrookGPU的设计目标是将GPU作为流式协处理器,通过流式编程模型将数据并行计算和算术密集型计算集成到一个熟悉的语言中。它通过编译器和运行时系统抽象化了GPU的硬件细节,使得开发者可以更方便地利用GPU的并行计算能力。
特点
- 数据并行性:允许开发者指定如何在不同数据上并行执行相同的操作。
- 算术密集型计算:鼓励开发者指定数据上的操作,以减少全局通信,增加局部计算。
- 简化编程模型:通过流和内核的概念,BrookGPU简化了GPU编程,降低了对图形硬件知识的要求。
应用场景
- BrookGPU适用于多种高性能计算场景,如图像处理、物理模拟、傅里叶变换(FFT)等。它通过利用GPU的大规模并行性,能够显著提升计算效率。
开源与支持
1.BrookGPU作为一个开源项目,提供了编译器和运行时系统,支持在多种GPU硬件上运行。它为开发者提供了一个通用的工具,用于探索GPU在通用计算中的潜力。
总的来说,BrookGPU是早期探索GPU通用计算的重要工具之一,为后续的GPU编程模型(如CUDA)奠定了基础。
2.2.2 BrookGPU的底层源代码
BrookGPU是一种软件,具体来说,它是一个编译器和运行时系统,用于在图形处理器(GPU)上进行通用计算。
BrookGPU的底层源代码主要是用C语言编写的。它的编译器(brcc)基于一个开源的C解析器cTool,并被修改以支持Brook语言的特定语法。此外,BrookGPU的运行时系统(BRT)提供了一个跨平台的接口,支持多种后端,包括OpenGL、DirectX以及CPU参考实现。
流(Streams)是BrookGPU中的一种数据结构,用于表示可以并行处理的数据集合。流的声明类似于C语言中的数组,但有一些特殊的规则和限制:
- 流使用尖括号
<>声明,例如float s<10, 10>表示一个二维流,包含100个浮点元素。 - 流的形状(Shape)指的是其维度,例如
<10, 10>表示一个10×10的二维流。 - 流的元素只能在内核(Kernels)中访问,或用
streamRead和streamWrite操作符在内存和流之间传输数据。 - 流不支持静态初始化,例如不能使用
float s<100> = {1.0f, 2.0f, ...}的方式初始化。
- 流使用尖括号
内核(Kernels)是BrookGPU中的一种特殊函数,用于对流中的数据进行并行操作。内核定义和调用方式为:
- 内核函数以
kernel关键字声明,返回类型为void,并且至少有一个流参数。 - 调用内核时,BrookGPU会隐式地对流中的每个元素执行内核函数。
- 内核可以接受输入流(只读)和输出流(只写),还可以接受常量参数。
- 内核函数以
以下是一个简单的BrookGPU程序示例,展示了流和内核的使用:
1 | // 定义一个内核函数,用于计算向量的线性组合 |
- 在这个例子中:
float4 x<100>,y<100>,result<100>声明了三个流,分别用于输入和输出。saxpy内核函数对每个流元素执行操作,计算a*x + y。streamRead和streamWrite用于在主机内存和流之间传输数据。
通过流和内核的概念,BrookGPU提供了一种高效且简洁的方式来利用GPU的并行计算能力,适用于图像处理、科学计算等场景。
3 各GPU支持的CUDA版本
3.1 查看显卡驱动版本号
当显卡驱动安装完成后,需要使用nvidia-smi命令查看英伟达显卡驱动版本。1
2
3
4
5
6
7
8
9
10
11
12显卡驱动信息,主要看driver API的CUDA版本,即Runtime API CUDA支持的最高版本
nvidia-smi
当前使用的CUDA的版本
nvcc -V
查看安装了几个CUDA,当前使用哪个版本的CUDA
ll /usr/local/
查看已安装的包的版本
conda list | grep cuda
conda list | grep torch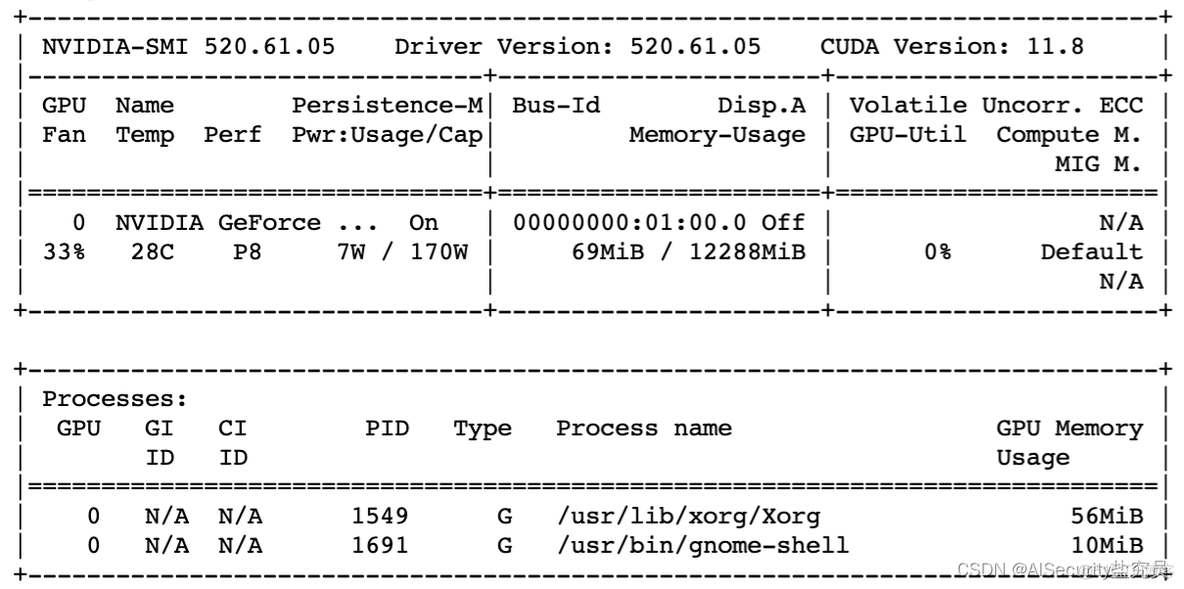
如上图所示,英伟达驱动版本为520.61.05,CUDA最高支持的版本为11.8。
3.2 查看显卡驱动版本号和CUDA版本对应关系
查看英伟达显卡驱动版本和CUDA版本的对应关系 —— 点击该链接:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
下图为CUDA工具包和CUDA小版本兼容性所需的最低驱动程序版本:
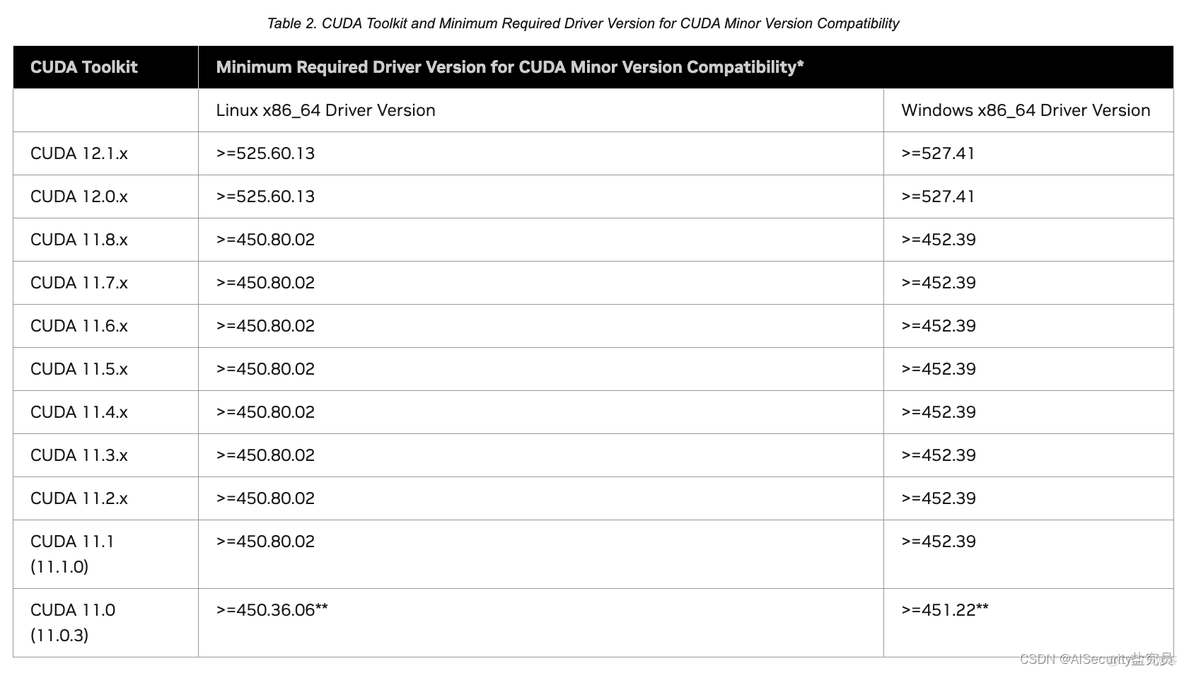
由于我工作站(Ubuntu 20.04 LTS)的英伟达驱动版本为520.61.05,从上图可以看出,我最高可以安装的CUDA版本为11.8.x。(注:CUDA 12.0.x和CUDA 12.1.x都要求英伟达驱动版本大于等于525.60.13,因此我的520.61.05不符合,所以我最高只能安装CUDA 11.8.x的版本)。
3.3 查看经典的CUDA版本号
由于我们最终是要安装pytorch,因此选取合适的CUDA进行安装是有必要的。CUDA和PyTorch之间存在版本依赖关系,这是因为PyTorch可以使用CUDA加速深度学习模型的训练和推理,需要与特定版本的CUDA兼容才能正常工作。以下是CUDA和PyTorch版本之间的关系:
- CUDA和PyTorch的版本兼容性:
- 不同版本的PyTorch需要与特定版本的CUDA兼容,以确保能够利用GPU的计算能力。这是因为PyTorch使用CUDA来执行深度学习操作。
- 在使用PyTorch之前,你应该查看PyTorch官方文档或GitHub仓库中的文档,以了解当前版本所支持的CUDA版本。通常,PyTorch的文档会明确说明支持的CUDA版本范围。
-示例:- 例如,如果你使用的是
PyTorch 1.8.0,官方文档可能会明确指出支持CUDA 11.1,因此你需要安装CUDA 11.1或兼容版本的CUDA驱动来与PyTorch 1.8.0一起使用。
- 例如,如果你使用的是
| pytorch版本 | torchvision版本 | cuda版本 | python版本 | 备注 |
|---|---|---|---|---|
| 0.4.0 | 0.2.2 | Cuda8.0 / 9.0 / 9.1 | [3.5, 3.7] | |
| 0.4.1 | 0.2.2 | Cuda8.0 / 9.0 / 9.2 | [3.5, 3.7] | |
| 1.0.0 | 0.2.1 | Cuda8.0 / 9.0 / 10.0 | [3.5, 3.7] | |
| 1.0.1 | 0.2.2 | Cuda9.0 / 10.0 | [3.5, 3.7] | |
| 1.1.0 | 0.3.0 | Cuda9.0 / 10.0 | [3.5, 3.7] | |
| 1.2.0 | 0.4.0 | Cuda9.2 / 10.0 | [3.5, 3.7] | |
| 1.3.0 | 0.4.1 | Cuda9.2 / 10.0 / 10.1 | [2.7, 3.7] | |
| 1.3.1 | 0.4.2 | Cuda9.2 / 10.0 / 10.1 | [2.7, 3.7] | |
| 1.4.0 | 0.5.0 | Cuda9.2 / 10.1 | [3.5, 3.8] | |
| 1.5.0 | 0.6.0 | Cuda9.2 / 10.1 / 10.2 | [3.5, 3.8] | |
| 1.5.1 | 0.6.1 | Cuda9.2 / 10.1 / 10.2 | [3.5, 3.8] | |
| 1.6.0 | 0.7.0 | Cuda9.2 / 10.1 / 10.2 | [3.5, 3.8] | |
| 1.7.0 | 0.8.1 | Cuda10.1 / 10.2/ 11.0 | [3.6, 3.8] | |
| 1.7.1 | 0.8.2 | Cuda10.1 / 10.2 / 11.0 | [3.6, 3.9] | |
| 1.8.0 | 0.9.0 | Cuda10.1 / 10.2 / 11.1 | [3.6, 3.9] | |
| 1.8.1 | 0.9.1 | Cuda10.1 / 10.2 / 11.1 | [3.6, 3.9] | |
| 1.9.0 | 0.10.0 | Cuda10.2 / 11.1 | [3.6, 3.9] | |
| 1.9.1 | 0.10.1 | Cuda10.2 / 11.1 | [3.6, 3.9] | |
| 1.10.0 | 0.11.1 | Cuda10.2 / 11.1 / 11.3 | [3.6, 3.9] | |
| 1.10.1 | 0.11.2 | Cuda10.2 / 11.1 / 11.3 | [3.6, 3.9] | |
| 1.10.2 | 0.11.3 | Cuda10.2 / 11.1 / 11.3 | [3.6, 3.9] | |
| 1.11.0 | 0.12.0 | Cuda11.1 / 11.3 / 11.5 | [3.7, 3.10] | |
| 1.12.0 | 0.13.0 | cuda10.2 / 11.3 / 11.6 | [3.7, 3.10] | |
| 1.13.0 | 0.14.0 | cuda11.6 / 11.7 | [3.7, 3.11] | |
| 1.13.1 | 0.14.1 | cuda11.6 / 11.7 | [3.7, 3.11] | |
| 2.0.0 | 0.15.0 | cuda11.7 / 11.8 | [3.8, 3.11] | |
| 2.0.1 | 0.15.2 | cuda11.7 / 11.8 | [3.8, 3.11] | |
| 2.1.0 | 0.16.0 | cuda11.8 / 12.1 | [3.8, 3.11] | |
| 2.1.1 | 0.16.1 | cuda11.8 / 12.1 | [3.8, 3.11] |
3.4 小结
确定PyTorch、CUDA和显卡驱动的版本并确保它们兼容,可以按照以下步骤进行:
确定显卡驱动版本:
- 在终端中执行
nvidia-smi命令。这个命令会显示当前系统上的NVIDIA显卡驱动版本以及相关信息。 - 记下显示的 NVIDIA 驱动版本号。例如,版本号可能类似于
465.19.01。
- 在终端中执行
确定 CUDA 版本:
- 通常,NVIDIA显卡驱动与CUDA版本一起安装。所以,你可以通过查看CUDA的版本来确定。
- 在终端中执行
nvcc --version命令来查看CUDA版本。 - 记下显示的CUDA版本号。例如,版本号可能类似于
11.1。
确定 PyTorch 版本:
- 使用Python代码来查看PyTorch的版本:
import torch; print(torch.__version__) - 记下显示的PyTorch版本号。例如,版本号可能类似于
1.8.1。
- 使用Python代码来查看PyTorch的版本:
检查兼容性:
- 一旦你确定了各个组件的版本号,你可以查阅PyTorch的官方文档,了解哪个版本的PyTorch与哪个版本的CUDA和显卡驱动兼容。通常,PyTorch的文档会明确说明支持的CUDA版本范围。
- 如果你的PyTorch版本与你的CUDA版本和显卡驱动版本不兼容,你可能需要升级或降级其中一个或多个组件,以确保它们能够良好地协同工作。
往往我们在实际项目时,起始首先确定的是PyTorch的版本,进而确定CUDA的版本,再根据CUDA的版本去查看自己平台的驱动是否支持。
参考链接1:深度学习|如何确定 CUDA+PyTorch 版本 - 腾讯云
4 CUDA、CUDA toolkit、CUDNN、NVCC关系
4.1 CUDA/cudnn/CUDA Toolkit/NVCC区别简介
- CUDA:为“GPU通用计算”构建的运算平台。
- cudnn:为深度学习计算设计的软件库。
- CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了Nvidia驱动程序、开发CUDA程序相关的开发工具包等可供安装的选项。包括CUDA程序的编译器、IDE、调试器等,CUDA程序所对应的各式库文件以及它们的头文件。
- CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用CUDA相关的功能时所依赖的动态链接库。不会安装驱动程序。
- NVCC是CUDA的编译器,只是CUDA Toolkit中的一部分
注:CUDA Toolkit完整和不完整的区别:在安装了CUDA Toolkit (Pytorch)后,只要系统上存在与当前的CUDA Toolkit所兼容的Nvidia驱动,则已经编译好的CUDA相关的程序就可以直接运行,不需要重新进行编译过程。如需要为Pytorch框架添加CUDA相关的拓展时(Custom C++ and CUDA Extensions),需要对编写的CUDA相关的程序进行编译等操作,则需安装完整的Nvidia官方提供的CUDA Toolkit。
4.2 CUDA Toolkit具体组成
一般的结构中,include 包含头文件,bin 包含可执行文件,lib 包含程序实现文件编译生成的library,src包含源代码,doc或help包含文档,samples包含例子。
- Compiler:NVCC
- Tools:分析器profiler、调试器debuggers等
- Libraries:科学库和实用程序库
- CUDA Samples:CUDA和library API的代码示例
- CUDA Driver:驱动,需要与“有CUDA功能的GPU”和“CUDA”都兼容。CUDA工具包都对应一个最低版本的CUDA Driver,CUDA Driver向后兼容。
4.3 NVCC简介
- NVCC其实就是CUDA的编译器,CUDA程序有两种代码, 在cpu上的host代码和在gpu上的device代码。
.cu后缀:cuda源文件,包括host和device代码
1 | nvcc编译例子 |
4.4 Runtime API CUDA(nvcc —version)
对于 Pytorch 之类的深度学习框架而言,其在大多数需要使用 GPU 的情况中只需要使用 CUDA 的动态链接库支持程序的运行( Pytorch 本身与 CUDA 相关的部分是提前编译好的 ),就像常见的可执行程序一样,不需要重新进行编译过程,只需要其所依赖的动态链接库存在即可正常运行。
Anaconda 在安装 Pytorch 等会使用到 CUDA 的框架时,会自动为用户安装对应版本的 Runtime API cudatoolkit,其主要包含应用程序在使用 CUDA 相关的功能时所依赖的动态链接库。在安装了 Runtime API cudatoolkit 后,只要系统上存在与当前的Runtime API cudatoolkit 所兼容的 Nvidia 驱动,则已经编译好的 CUDA 相关的程序就可以直接运行,而不需要安装完整的 Nvidia 官方提供的 CUDA Toolkit .
pytorch和cudatoolkit版本并不是一一对应的关系,一个pytorch版本可以有多个cudatoolkit版本与之对应。例如1.5.1版本的pytorch,既可以使用9.2版本的cudatoolkit,也可以使用10.2版本的cudatoolkit。
可以查看pytorch官网对应的:https://pytorch.org/get-started/previous-versions/
只指定pytorch版本来安装不一定是能work的,例如执行conda install pytorch=X.X.X -c pytorch时,conda会自动为你选择合适版本的 Runtime API cudatoolkit。但conda只能保证你的pytorch和cudatoolkit版本一定是对应的,但并不能保证pytorch可以正常使用,因为系统的Nvidia Driver有可能不支持你所安装的cudatoolkit版本。
所以,除非你对你的Nvidia driver版本很有自信,否则,还是先查看系统Driver API CUDA的版本
当然,如果你对pytorch版本有特别的要求,你可以同时指定pytorch和cudatoolkit的版本。如果这两个版本不能兼容,系统会报错
参考链接1:一文讲清楚CUDA、CUDA toolkit、CUDNN、NVCC关系 - CSDN
参考链接2:显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? - marsggbo的文章 - 知乎
5 安装CUDA
5.1 下载CUDA安装包
CUDA官方下载链接:https://developer.nvidia.com/cuda-toolkit-archive
进入CUDA官方的下载链接后,查找自己需要下载的版本(以CUDA 11.3.1为例):

点击自己需要下载的版本,一次选择操作系统、系统架构、系统版本和安装方式,在这里推荐使用 runfile(local) 的安装方式。
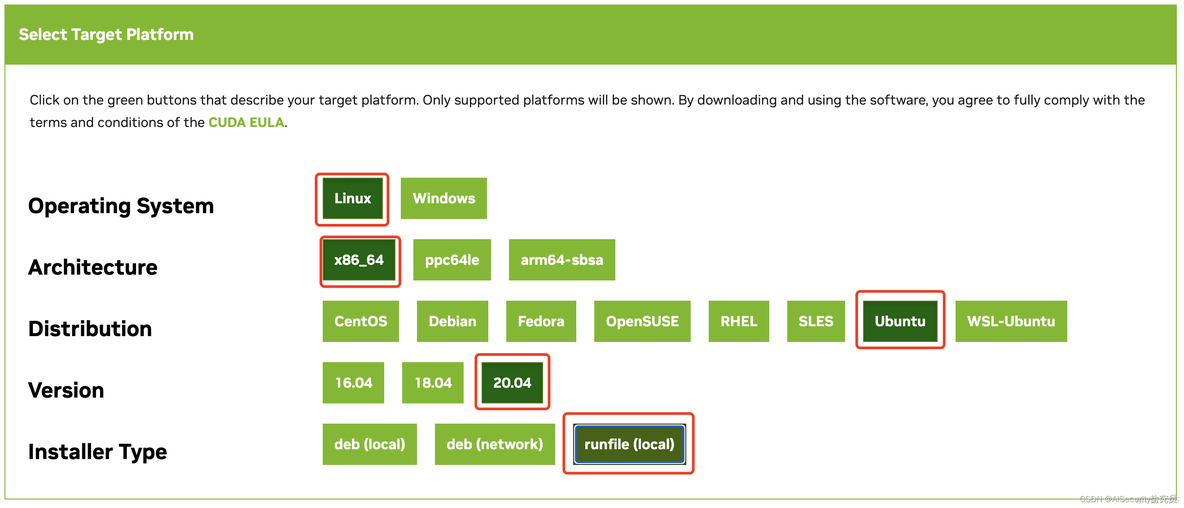
完成上述操作后,网页下方弹出安装的命令,如下图所示:
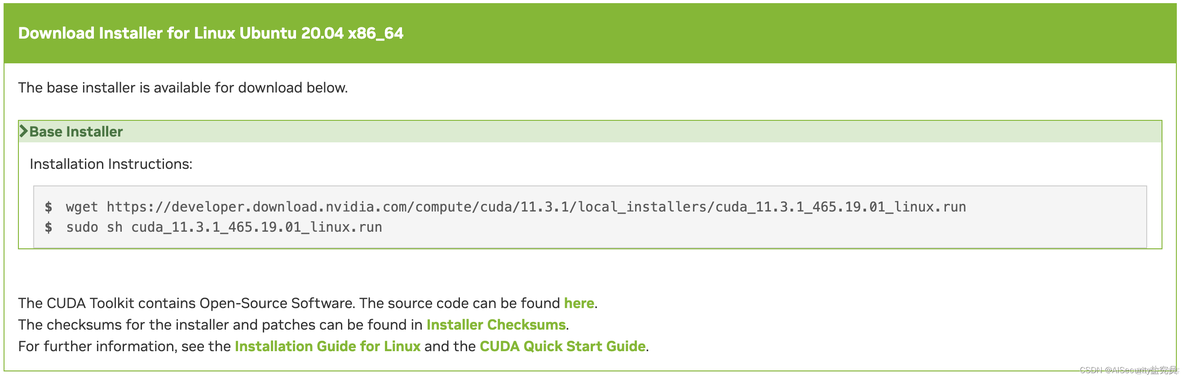
5.2 执行CUDA安装
在Ubuntu 20.04 LTS系统的命令行中,按照以下命令进行安装。1
2
3
4
5# 第一步:使用wget命令下载安装包
wget https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run`
# 第二步:执行安装脚本
sudo sh cuda_11.3.1_465.19.01_linux.run
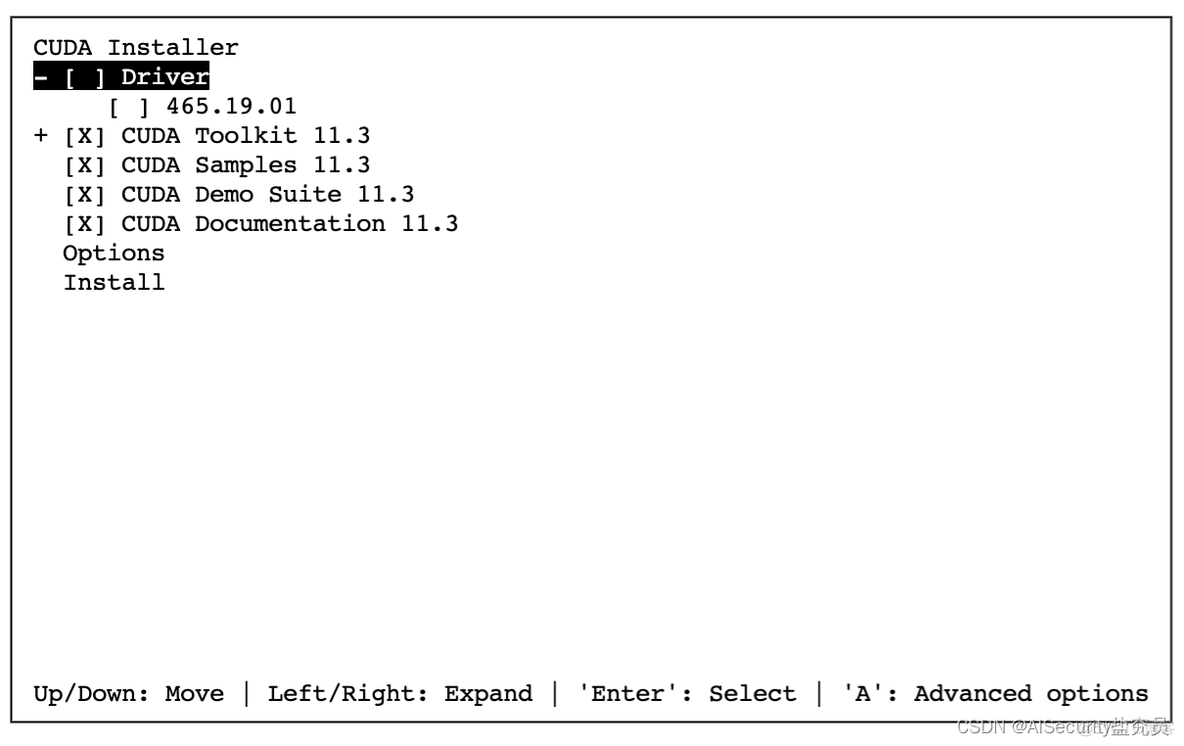
执行上述命令后,等待1分钟左右,系统会弹出安装的协议,问你Do you accept the above EULA? 你需要在后面的光标处,填写accept,然后敲回车。

然后系统询问安装的内容,注意!!! 一定要把Driver驱动这个给去掉(按空格键可以将 X 去掉),如果[ ]内是X说明是要安装的;如果[ ]是空,说明不安装。选择完成后,然后移动至Install 处,敲击回车。
安装完成后,会在/usr/local目录下产生cuda-11.3目录,如下图所示:
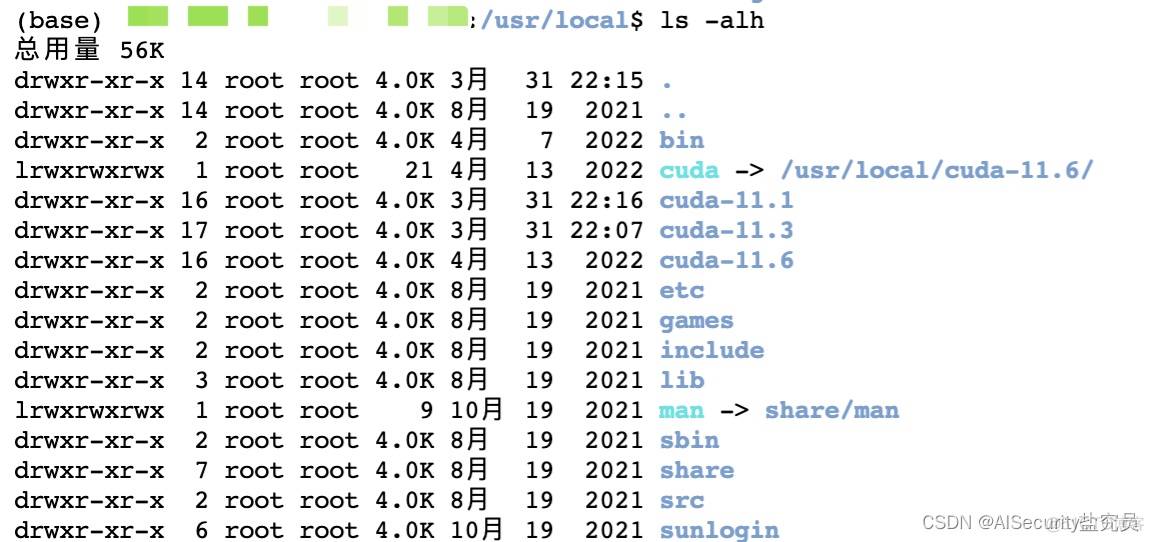
这样说明CUDA-11.3版本安装完成了!
5.3 配置环境变量
使用 vim ~/.bashrc 命令进行编辑,在文件末尾添加下列代码:
1 | # cuda |
然后执行 source ~/.bashrc 刷新文件使其生效。
5.4 CUDA多版本管理
从图中可以看出,系统安装了11.1、11.3和11.6版本。
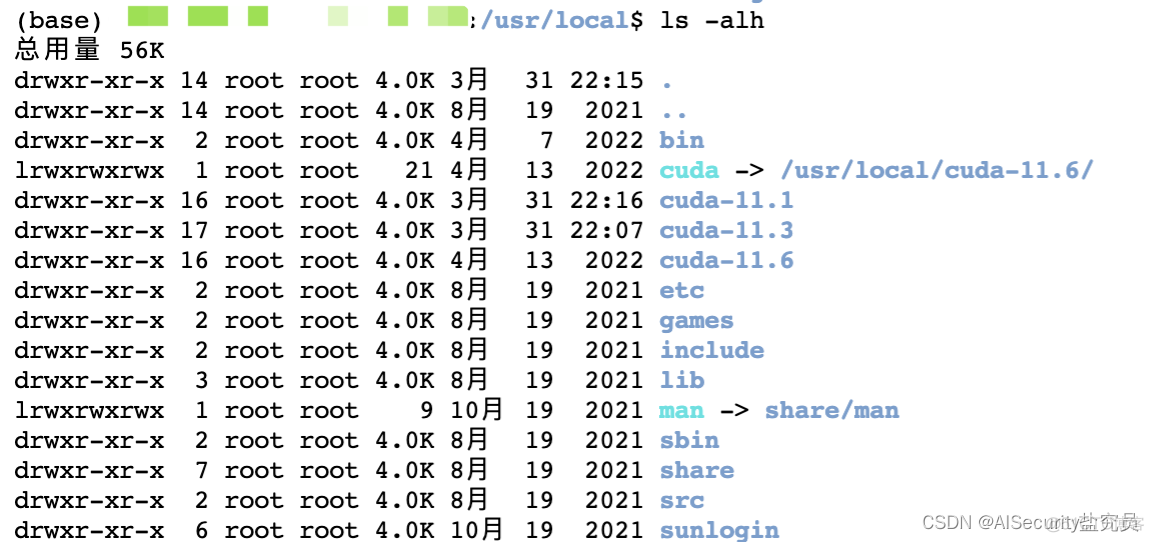
由于环境变量的地址为/usr/local/cuda,且我们可以从图中发现目录下存在一个软链接,即:/usr/local/cuda指向了/usr/local/cuda-11.6链接,说明此时尽管安装了CUDA 11.1和 CUDA 11.3版本,但系统默认的环境版本为11.6。如何进行多版本的切换呢,比如想把CUDA版本切换成11.3版本(但是要保留CUDA 11.1和11.6版本),我们只需要修改软链接即可,将CUDA 11.3的软链接链接到cuda目录下,代码如下:
1 | # 删除原有的软链接 |
软链接重新生成后,使用nvcc -V命令可以查看当前的CUDA版本,如下所示:1
2
3
4
5nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Sun_Mar_21_19:15:46_PDT_2021
Cuda compilation tools, release 11.3, V11.3.58
Build cuda_11.3.r11.3/compiler.29745058_0





